Introdução
Os Transformers são uma arquitetura de redes neurais que revolucionou o campo da Inteligência Artificial, especialmente em Processamento de Linguagem Natural (PLN). Introduzidos em 2017 no influente artigo “Attention Is All You Need” do Google, eles representaram uma mudança de paradigma ao superar as limitações das redes neurais recorrentes (RNNs) usadas até então. Diferentemente das RNNs, que processavam sequências passo a passo e tinham dificuldades com dependências de longo alcance, os Transformers conseguem processar todos os elementos de uma sequência em paralelo e capturar relações de longo prazo entre os dados.
Essa inovação fez dos Transformers a base de modelos avançados de linguagem como BERT e GPT (Generative Pre-trained Transformer) – sendo este último a espinha dorsal do ChatGPT. Hoje, a arquitetura Transformer não só domina tarefas de PLN (tradução automática, resumo de textos, respostas a perguntas etc.), mas também se estendeu a outras áreas como visão computacional (por exemplo, Vision Transformers), reconhecimento de fala e até bioinformática. Neste artigo, vamos explicar de forma acessível como funciona a arquitetura Transformer, detalhando seus principais componentes e mostrando exemplos práticos de seu funcionamento.
O que é a Arquitetura Transformer?
Em essência, um Transformer é um modelo de deep learning projetado para transformar uma sequência de entrada em outra sequência de saída, aprendendo a prestar atenção nas partes mais relevantes da informação. Diferentemente de modelos anteriores que liam palavra por palavra em ordem, o Transformer olha globalmente para a sequência através de um mecanismo de auto-atenção (self-attention). Isso significa que ele pode ponderar diferentes partes da entrada simultaneamente, determinando quais palavras (ou partes dos dados) são mais importantes para entender o contexto geral.
A arquitetura clássica de um Transformer segue um formato encoder-decoder (codificador-decodificador). O Encoder (codificador) lê a sequência de entrada completa e produz representações internas (vetores contextuais) que resumem o significado de cada elemento com base em seu contexto. Em seguida, o Decoder (decodificador) recebe essas representações e gera a sequência de saída passo a passo, produzindo um token (palavra ou parte da palavra) de cada vez. Durante esse processo, o decoder utiliza o mecanismo de atenção para olhar tanto para o que já gerou quanto para a informação vinda do encoder, assegurando que a saída seja coerente e relevante ao conteúdo de entrada.
Por que isso é importante? Porque permite que o modelo trate de forma eficiente tarefas complexas como tradução automática ou geração de texto. Por exemplo, em tradução, o encoder cria um “entendimento” de uma frase em português, e o decoder usa esse entendimento para produzir a frase equivalente em inglês, tudo isso mantendo o contexto e a ordem lógica das palavras. A capacidade de paralelizar o processamento e capturar dependências distantes tornou os Transformers extremamente poderosos, reduzindo o tempo de treinamento e aumentando a qualidade dos resultados em comparação com modelos antigos baseados em recorrência.
Componentes Principais da Arquitetura Transformer
Vamos agora dissecar os principais componentes que formam um Transformer. Cada um desses elementos desempenha um papel específico para que, juntos, possamos converter uma sequência de entrada (como uma frase) em uma sequência de saída (como uma tradução ou resposta). A figura abaixo ilustra a arquitetura típica de um Transformer com seus componentes centrais, incluindo o encoder à esquerda e o decoder à direita, juntamente com os fluxos de atenção:
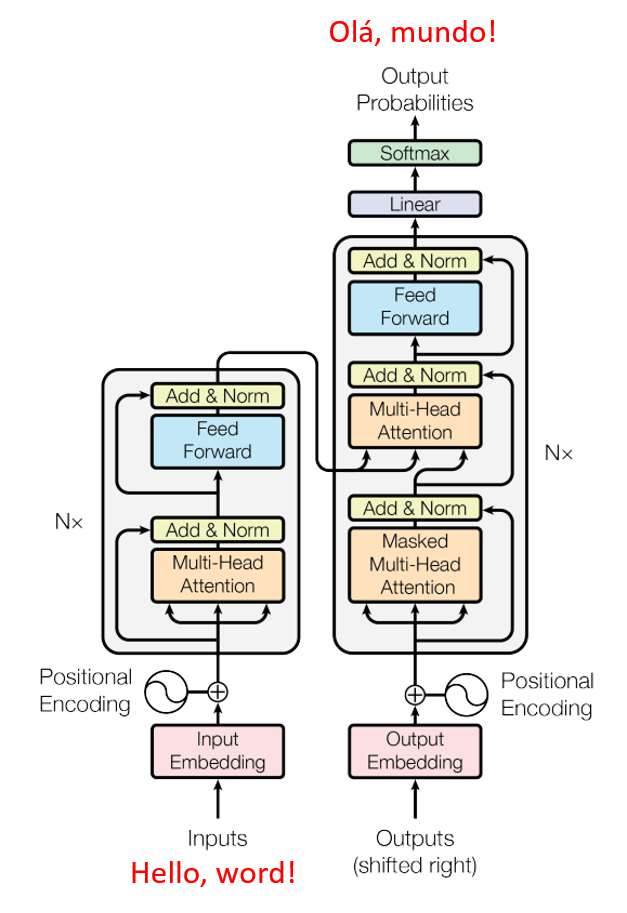
Arquitetura geral de um Transformer, mostrando à esquerda as camadas do encoder e à direita as camadas do decoder. O diagrama destaca o uso de múltiplas camadas de atenção (Multi-Head Attention) e feed-forward em ambos, bem como a conexão entre encoder e decoder via mecanismos de atenção.
Embeddings de Entrada (Input Embedding)
O primeiro passo em um Transformer é converter os dados simbólicos da entrada (por exemplo, palavras ou tokens) em uma representação numérica que a rede neural consiga processar. Isso é feito pelos embeddings de entrada. Um embedding nada mais é do que um vetor de números em alta dimensão que representa uma palavra (ou parte de palavra) de forma que palavras com contextos ou significados semelhantes fiquem com vetores parecidos. Em outras palavras, o modelo possui uma “tabela” de embeddings aprendida durante o treinamento, e cada token de entrada é mapeado para um vetor nessa tabela.
Por exemplo, suponha que o vocabulário do modelo contenha as palavras “gato” e “cachorro”. Cada uma terá um vetor de embedding associado. Espera-se que esses vetores estejam posicionados de forma que reflitam alguma relação – talvez “gato” e “cachorro” tenham vetores relativamente próximos pois ambos são animais domésticos, enquanto a palavra “banana” teria um vetor bem diferente. Após a tokenização (quebra da frase em tokens menores), cada token da sequência de entrada é substituído pelo seu vetor embedding. Assim, a frase “O gato subiu no telhado” torna-se uma sequência de vetores numéricos correspondentes a [“O”, “gato”, “subiu”, “no”, “telhado”]. Esses vetores iniciais carregam informações semânticas das palavras, mas não carregam ainda informação de posição na frase.
Codificação Posicional (Positional Encoding)
Como os Transformers não possuem um senso de ordem sequencial inerente (ao contrário das RNNs que leem passo a passo), é necessário adicionar manualmente informações de posição dos tokens na sequência. É aí que entra a Codificação Posicional. A codificação posicional é um conjunto de vetores que são somados (ou concatenados, dependendo da implementação) aos embeddings de entrada para informar ao modelo a posição de cada palavra na frase.
Uma forma clássica de codificação posicional, descrita no paper original, utiliza funções senoidais e cossenoidais de diferentes frequências para gerar padrões numéricos únicos para cada posição. Sem entrar em fórmulas matemáticas complicadas, imagine que para a posição 1 o modelo adiciona um pequeno padrão de valores ao vetor da primeira palavra; para a posição 2, um padrão diferente, e assim por diante. Esses padrões são construídos de modo que posições próximas tenham codificações semelhantes, enquanto posições distantes apresentam codificações bem diferentes. Assim, o Transformer consegue distinguir “gato” como a 2ª palavra da sequência, e não apenas reconhecer que a palavra “gato” apareceu em algum lugar.
Em resumo, posicional encoding fornece ao modelo noção de ordem: ele passa a saber quem é o primeiro token, o segundo, etc., até o último. Essa etapa é crucial porque, sem ela, o modelo veria a frase como um “saco de palavras” sem ordem e poderia confundir significados (por exemplo, “Maria ama João” vs “João ama Maria” têm as mesmas palavras, mas em ordens diferentes, o que muda o sentido).
Encoder (Codificador)
O Encoder é a parte do Transformer responsável por ler a sequência de entrada (após ela ter passado pelo embedding e pela codificação posicional) e gerar uma representação interna rica em contexto. Ele é composto por várias camadas idênticas empilhadas – por exemplo, o Transformer original usava 6 camadas de encoder, uma após a outra. Cada camada do encoder realiza duas sub-tarefas principais: primeiro aplica um mecanismo de atenção nos tokens da própria entrada, e depois passa o resultado por uma camada feed-forward (que veremos adiante), além de aplicar técnicas de normalização e conexões de atalho (residuais) para facilitar o treinamento.
- Atenção no Encoder (Self-Attention): Em cada camada do encoder, o modelo aplica auto-atenção nos tokens de entrada. Auto-atenção significa que cada posição da sequência vai olhar para todas as outras posições da sequência a fim de determinar de quais palavras ele precisa “prestar atenção” para melhor entender o contexto. Por exemplo, se a frase de entrada for “O gato subiu no telhado”, quando o encoder estiver processando o token “gato”, a atenção permite que o modelo considere também informações de tokens como “telhado” ou “subiu” para construir uma representação contextual de “gato”. Essa etapa captura as relações entre palavras: o modelo aprende, por exemplo, que “gato” está relacionado a “subiu no telhado” e não a outra coisa fora de contexto.
- Saída do Encoder: Após passar pelas camadas de atenção e feed-forward, o encoder produz uma série de vetores de representações contextuais – um vetor para cada posição/token de entrada. Cada vetor agora carrega não só a informação original do token, mas também informações do contexto inteiro da frase. No nosso exemplo, o vetor correspondente a “gato” carregará informações de que “subiu no telhado”, indicando que o gato é quem realizou a ação de subir, etc. Esses vetores de saída do encoder serão então fornecidos ao decoder para ajudar a gerar a sequência de saída.
Resumindo, o encoder atua como o “entendedor”: ele lê toda a frase de entrada e produz um mapa de significados espalhado em vetores, que condensa as relações entre as palavras de entrada.
Decoder (Decodificador)
Se o encoder é o responsável por entender a entrada, o Decoder é o responsável por produzir a saída desejada (por exemplo, a frase traduzida ou a resposta a uma pergunta). Assim como o encoder, o decoder também é composto de várias camadas empilhadas idênticas (novamente, 6 camadas no modelo original, como exemplo). Entretanto, as camadas do decoder têm uma estrutura um pouco diferente, pois elas precisam integrar duas fontes de informação: (1) a saída do encoder (que contém o contexto da entrada) e (2) os tokens já gerados pelo próprio decoder até o momento atual.
Cada camada típica de decoder inclui três subcomponentes principais:
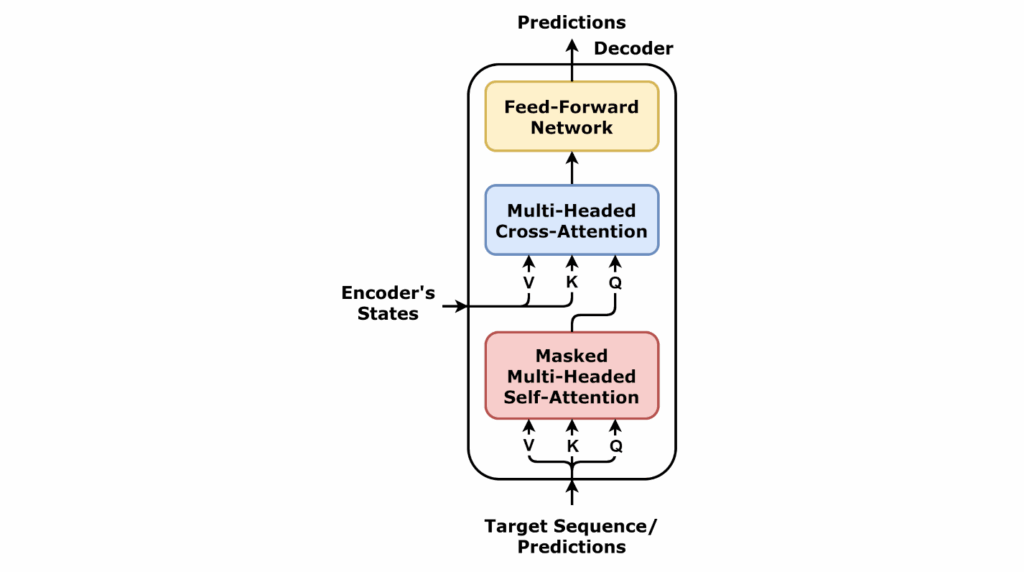
- Atenção Mascarada (Masked Self-Attention): O decoder também usa auto-atenção nas posições da sequência de saída que já foram geradas. Contudo, para garantir que o modelo não olhe para o futuro (isto é, tokens de saída que ele ainda não gerou), aplica-se uma máscara causal durante a atenção. Essa atenção mascarada faz com que, ao gerar o token na posição t, o modelo só enxergue os tokens anteriores a t (incluindo o próprio token anterior imediato), e não os tokens seguintes. Em outras palavras, o decoder “tapa os olhos” do modelo para qualquer informação futura na sequência de saída, assegurando que a geração seja feita de forma autorregressiva (um passo de cada vez, sem trapaça). Falaremos mais sobre essa máscara adiante, mas o importante é: no decoder, a auto-atenção é mascarada para evitar que ele use indevidamente a resposta que ainda não foi produzida.
- Atenção no Encoder (Cross-Attention): Além da auto-atenção mascarada, cada camada do decoder tem uma etapa de atenção cruzada que permite ao decoder consultar os vetores do encoder. Neste estágio, o decoder foca nas partes relevantes da sequência de entrada original, utilizando os vetores contextuais produzidos pelo encoder. Por exemplo, se o encoder analisou a frase em português “O gato subiu no telhado” e o decoder está traduzindo para o inglês, no momento de gerar a palavra “cat”, o decoder vai olhar para o vetor do encoder correspondente a “gato” para obter o significado correto e assegurar que “cat” é a tradução certa. Essa atenção cruzada garante que a saída se baseie efetivamente na entrada, combinando o contexto da frase original em cada passo de geração da frase traduzidaen. (Note que na atenção cruzada não precisamos de máscara, pois toda a entrada já é conhecida e processada pelo encoder.)
- Feed-Forward: Por fim, assim como no encoder, cada camada do decoder também tem uma subcamada de feed-forward, que aplica uma transformação não-linear em cada posição, refinando ainda mais as representações após as etapas de atenção.
O decoder funciona de forma iterativa durante a geração. Ele começa recebendo um símbolo inicial (geralmente um token especial indicando início de sequência, como <SOS> ou <|endoftext|> no caso de modelos de linguagem) e, com base nisso e nos vetores do encoder, gera uma probabilidade para qual deveria ser o primeiro token de saída. Seleciona-se o token de maior probabilidade (por exemplo, a palavra “The” se estivermos traduzindo “O gato…”) e então alimenta-se esse token de volta no decoder para prever o próximo, e assim por diante. Graças à atenção mascarada, quando o decoder vai prever a segunda palavra, ele leva em conta apenas que a primeira palavra gerada foi “The” e consulta o encoder para ver o que deveria vir depois dado “O gato…”. Esse processo se repete até um token especial de fim de sequência ser gerado ou até atingir o limite de comprimento da saída.
Em resumo, o decodificador é o “escritor” do Transformer: ele produz o texto de saída um passo por vez, garantindo coerência com o que já foi escrito (via atenção mascarada) e fidelidade ao conteúdo da entrada (via atenção cruzada com o encoder).
Atenção Multi-Cabeças (Multi-Head Attention)
O mecanismo de atenção é tão importante que merece uma explicação dedicada. No Transformer, a atenção é implementada de forma denominada Multi-Head Attention, ou atenção de múltiplas cabeças. Mas o que isso significa?
Quando dizemos que o modelo realiza atenção, internamente ele está calculando pontuações de similaridade entre vetores (como entre cada par de palavras numa frase, por exemplo). Seria como perguntar: “Ao analisar a palavra X, quanta atenção devo dar a cada uma das outras palavras Y, Z, … para entender o significado de X no contexto?” Esse cálculo é feito transformando os vetores de cada palavra em três conjuntos de vetores menores chamados Queries (Consultas), Keys (Chaves) e Values (Valores) e então computando produtos internos entre queries e keys para obter uma medida de relevância de cada palavra para as outras. Embora não entremos em detalhes matemáticos, é importante saber que atenção é um tipo de filtro contextual: ele destaca no Value aquilo que o Query considera importante, usando o Key como referência.
Agora, o “pulo do gato” do Transformer foi perceber que não precisava fazer uma única atenção, mas sim várias atenções em paralelo, cada uma focando em um aspecto diferente da relação entre as palavras. Daí vem o termo multi-head (múltiplas cabeças): cada “cabeça” de atenção é como um sub-mecanismo de atenção independente.
Por exemplo, imagine uma frase longa – uma cabeça de atenção poderia se especializar em relacionar substantivos com adjetivos que os descrevem, enquanto outra cabeça poderia aprender a relacionar pronomes com os sujeitos corretos, e outra poderia focar em conexões de sequência temporal (quem veio antes/depois). Quando o modelo processa a frase, todas essas cabeças operam simultaneamente, cada uma gerando seu próprio conjunto de pesos de atenção. Em seguida, os resultados de todas as cabeças são combinados (concatenados e projetados de volta a um tamanho único) para produzir a saída final da camada de atenção. Isso dá ao modelo a capacidade de capturar diferentes tipos de relação na linguagem ao mesmo tempo – algo análogo a ter múltiplas perspectivas ou filtros sobre os dados.
Em termos práticos, se tivermos, digamos, 8 cabeças de atenção, o vetor de cada palavra será processado de 8 maneiras ligeiramente diferentes em paralelo. Talvez a 1ª cabeça veja que “gato” está ligado a “telhado” (quem sobe em telhado geralmente é gato), a 2ª cabeça pode perceber relação entre “O” e a estrutura sintática do resto da frase, a 3ª pode notar algum outro padrão linguístico, e assim por diante. Ao fim, o modelo consolida essas informações. A atenção multi-cabeças torna o Transformer muito poderoso em capturar nuances do idioma, porque nenhuma única cabeça de atenção precisa tentar aprender tudo – cada uma pode se especializar em um aspecto, e o conjunto oferece uma compreensão mais completa.
Atenção Mascarada (Masked Attention)
Mencionamos brevemente a atenção mascarada ao explicar o decoder, mas vale reforçar o conceito. A atenção mascarada é simplesmente o mecanismo de atenção com uma restrição adicional: impedir que certos elementos “enxerguem” outros durante o cálculo da atenção. No caso do Transformer original para PLN (Processamento de Linguagem Natural), essa máscara é usada no decoder para alcançar a propriedade de auto regressão.
Funciona assim: o decoder precisa gerar a saída um token de cada vez, sem conhecer o futuro. Então, quando calculamos a atenção para uma determinada posição do decoder (por exemplo, posição 3 da frase de saída), nós mascaramos todas as posições seguintes (4, 5, 6, …) de modo que a posição 3 não receba nenhuma informação das posições 4 em diante. Na prática, matematicamente, isso significa atribuir um peso de atenção zero (ou -∞ antes do softmax, tecnicamente) para qualquer conexão que “aponte” para o futuro. Dessa forma, a posição 3 só poderá se atentar às posições 1 e 2 (as já geradas) e a ela mesma – nunca à 4, 5 etc., porque essas ainda não foram geradas.
Essa técnica garante que, durante o treinamento, o modelo aprenda a prever a próxima palavra apenas com base no passado e no presente, exatamente como terá que fazer na hora de uso (inferência). É a atenção mascarada que torna possível o casamento entre o mecanismo de atenção e a geração sequencial de texto. Sem ela, o modelo trapacearia vendo a frase inteira de uma vez no decoder, o que não condiz com a realidade de gerar passo a passo.
Um detalhe interessante: para tarefas diferentes, usam-se máscaras diferentes. Por exemplo, no treinamento do BERT (um modelo apenas de encoder), utiliza-se masked language modeling, onde algumas palavras da entrada são mascaradas aleatoriamente e o modelo tenta prevê-las – mas isso é um “mascaramento” de outro tipo, não confundir com a atenção mascarada do decoder. No contexto de Transformer encoder-decoder para geração de texto, quando falamos masked attention, estamos quase sempre nos referindo a essa máscara causal no decoder que bloqueia o fluxo de informação do futuro para o passado, garantindo a causalidade correta na geração.
Camadas Feed-Forward
Além das camadas de atenção, cada bloco do Transformer (tanto no encoder quanto no decoder) contém uma camada de Feed-Forward. Esta camada é essencialmente uma rede neural totalmente conectada que atua separadamente em cada posição da sequência. Em outras palavras, após a etapa de atenção em uma camada, nós pegamos o vetor de cada posição (palavra) e passamos por uma pequena rede neural (geralmente duas camadas densas com uma ativação não-linear no meio, por exemplo uma camada linear, seguida de ReLU, seguida de outra linear). Essa sub-rede feed-forward transforma o vetor, combinando as informações que vieram da atenção de forma mais complexa e gerando novas representações para aquela posição.
Por que isso é necessário? Pense que a atenção serve para misturar informações entre diferentes palavras (relacionar “quem com quem”). Já a camada feed-forward serve para processar e extrair características mais abstratas de cada palavra depois de levar em conta essas relações. É como dizer: “Agora que considerei o contexto, deixe-me refinar a representação desta palavra através de uma pequena rede neural.” Essas camadas aumentam o poder de expressão do modelo, permitindo que combinações não lineares de informações sejam aprendidas.
Importante notar que as camadas feed-forward atuam de forma individual em cada posição, sem interação direta entre posições. Toda a interação entre diferentes posições (palavras) acontece mesmo na etapa de atenção; já a etapa feed-forward enriquece cada posição independentemente.
Cada camada completa do Transformer, portanto, faz: atenção -> feed-forward, com algumas técnicas auxiliares importantes: as chamadas conexões residuais (o famoso skip connection, onde a entrada original de uma subcamada é somada à saída dela, ajudando no fluxo de gradiente e estabilização do treinamento) e a normalização de camada (layer normalization, para manter os valores numéricos estáveis). Essas técnicas garantem que possamos empilhar muitas camadas sem que o treinamento fique instável. Mas para o nosso entendimento conceitual, basta lembrar: atenção e feed-forward se alternam em camadas para construir o poder do Transformer.
Transformers em Modelos de Linguagem como o ChatGPT
Agora que entendemos os blocos de construção dos Transformers, vamos ver como eles são aplicados em modelos de linguagem de ponta, como o ChatGPT.
O ChatGPT (baseado na família GPT da OpenAI) é essencialmente um Transformer de decoder apenas, mas em escala gigantesca. O nome GPT significa Generative Pre-trained Transformer, indicando exatamente que a arquitetura central é um Transformer gerador, pré-treinado em uma quantidade massiva de textos. Diferente do modelo encoder-decoder original (feito para tarefas como tradução), modelos como GPT usam somente o lado do decoder do Transformer, treinados de forma auto regressiva para prever o próximo token em sequências de texto. Isso quer dizer que eles aprendem a continuar qualquer texto dado, usando a atenção mascarada para não “espiar o futuro”, conforme explicamos.
No ChatGPT, o processo funciona assim: primeiro, a entrada do usuário (prompt) é tokenizada e incorporada (embeddings) exatamente da forma que descrevemos. Esses tokens de entrada servem como contexto inicial que o modelo irá usar para gerar uma continuação. Como o ChatGPT é um decoder-only, pode-se imaginar que ele trata a conversa inteira (instrução do usuário + seu próprio texto gerado até agora) como uma grande sequência que precisa prever passo a passo o próximo token. Internamente, há dezenas de camadas de atenção multi-cabeças e feed-forward trabalhando em conjunto. Por exemplo, a versão GPT-3 do modelo (no qual o ChatGPT se baseou inicialmente) tinha 96 camadas e 175 bilhões de parâmetros – todos esses parâmetros ajustando os mecanismos de atenção e feed-forward para conseguir modelar a linguagem de forma extremamente rica.
Quando você faz uma pergunta ao ChatGPT, ele começa com todos os seus tokens de entrada já conhecidos (nesse caso, não há encoder separado – o próprio histórico de conversa serve como base). Em seguida, ele vai gerando a resposta token por token. A atenção mascarada garante que, ao gerar cada token, o ChatGPT considera apenas o que já foi gerado antes e a entrada do usuário, sem nunca fugir da ordem causal. A atenção multi-cabeças dentro dele permite que o modelo recupere informações relevantes talvez ditas há vários parágrafos atrás na conversa (dependendo da janela de contexto), mantendo coerência e contexto. E as camadas de feed-forward aplicadas em cada posição ajudam a compor ideias mais complexas a partir daquele contexto, permitindo respostas que soam articuladas e completas.
Resumindo, o ChatGPT utiliza a arquitetura Transformer para entender o contexto de uma conversa e gerar respostas coerentes e relevantes. Toda vez que ele produz uma palavra, é o mecanismo de atenção trabalhando “freneticamente” para determinar quais partes do contexto (talvez uma pergunta feita, ou um detalhe mencionado anteriormente) são importantes para aquela próxima palavra. É incrível notar que, embora não haja um encoder-decoder separados em GPT, o próprio prompt de entrada funciona como “encoder implícito” – ou seja, o início da sequência fornece o contexto que depois partes mais adiante da sequência (a resposta) vão utilizar via atenção cruzada. Conceitualmente, é o mesmo princípio.
Vale mencionar que, além do treinamento padrão para “prever o próximo token”, o ChatGPT passou por etapas de ajuste fino, incluindo Aprendizado por Reforço com Feedback Humano (RLHF), para moldar as respostas de forma mais alinhada ao que usuários consideram útil ou apropriado. Mas essas são camadas adicionais sobre a arquitetura; o “esqueleto” que gera as frases continua sendo o Transformer.
Em suma, modelos de linguagem modernos como ChatGPT são Transformers em sua essência. Eles herdam a capacidade de lidar com dependências longas, contexto complexo e geração fluida diretamente da arquitetura Transformer, apenas escalando para modelos muito maiores e treinados com volumes de dados sem precedentes. Sem os Transformers, avanços como o ChatGPT simplesmente não teriam sido possíveis na forma e qualidade que vemos hoje.
Exemplo Prático Passo a Passo
Para fixar ideias, vamos passar por um exemplo prático de como um Transformer opera do começo ao fim. Considere que queremos usar um Transformer para traduzir uma frase simples do português para o inglês, por exemplo: Entrada: “O gato está no telhado.” Saída esperada: “The cat is on the roof.”
Vamos acompanhar o que acontece, de forma simplificada, em cada etapa:
- Tokenização: A frase de entrada é dividida em tokens. Aqui, poderíamos ter os tokens: [“O”, “gato”, “está”, “no”, “telhado”, “.”]. A frase vetorizada ficaria assim: [46, 342, 4428, 1207, 19260, 912, 19227, 71, 2172]. (Muitos modelos quebrariam ainda mais, mas manteremos palavra a palavra para facilitar).
- Embedding + Positional Encoding: Cada token é convertido em um vetor de embedding. Então, somamos a codificação posicional correspondente à posição de cada token. Agora temos uma sequência de vetores numéricos posicionais:
[e_O+p_1, e_gato+p_2, e_está+p_3, e_no+p_4, e_telhado+p_5, e_.+p_6], onde e_palavra é o vetor de embedding da palavra e p_i é o vetor de posição i. - Encoder – Camada 1 (Atenção): Os vetores entram na primeira camada do encoder. Aqui, a atenção será calculada para cada par de palavras. O modelo determina, por exemplo, que “gato” e “telhado” têm alta relevância mútua (porque o gato está no telhado), que “O” provavelmente se conecta a “gato” (artigo associado ao sujeito), e assim por diante. Cada cabeça de atenção pode focar em um aspecto: uma pode ligar “gato” com “telhado”, outra pode ligar “está” com “no telhado” (reconhecendo a locução “estar em”), etc. O resultado da atenção são novos vetores para cada posição, agora misturados com informações contextuais das outras palavras relevantes.
- Encoder – Camada 1 (Feed-Forward): Os vetores resultantes da atenção passam pelas redes feed-forward posição-por-posição, refinando as informações. Suponha que o vetor do “gato” após a atenção incorporou informação de “telhado” indicando que o gato está em cima de algo. A feed-forward pode extrair esse conceito de “estar em cima de” e codificá-lo de forma mais evidente no vetor do “gato”. (Isso é apenas uma interpretação intuitiva.) Ao final dessa camada, temos vetores atualizados para cada palavra.
- Encoder – Camadas 2 a N: O processo de atenção e feed-forward se repete em cada camada subsequente do encoder. Com várias camadas, o modelo consegue construir representações cada vez mais abstratas e de alto nível. Depois da última camada do encoder, cada token da entrada agora está representado por um vetor altamente contextualizado – ele “sabe” sobre toda a frase. Por exemplo, o vetor final correspondente a “telhado” saberá que alguém (um gato) está em cima dele, e o vetor de “gato” saberá que ele está em cima de algo (telhado).
- Início do Decoder: Agora entra em ação o decoder para gerar a frase em inglês. Inicialmente, nenhum token de saída foi gerado, então começamos com um token especial de início de sequência
<SOS>(vamos representar como “[inicio]”). Esse token passa primeiro pela etapa de embedding posicional do decoder, similar ao encoder. - Decoder – Camada 1 (Atenção Mascarada): Com “[inicio]” como o único token gerado até agora, o decoder calcula a atenção mascarada. Como só há um token, ele só pode se prestar atenção a si mesmo – nada mais a fazer aqui neste primeiro passo. (A máscara não muda nada quando só há um token.) O “[inicio]” então é processado pela feed-forward da camada 1 do decoder, preparando um vetor de estado interno inicial.
- Decoder – Camada 1 (Atenção Cruzada): Ainda na camada 1 do decoder, agora ocorre a atenção cruzada usando o vetor do decoder (proveniente de “[inicio]”) em relação aos vetores do encoder (provenientes de “O gato está no telhado .”). Aqui, o decoder vai tentar extrair da representação do encoder a informação necessária para produzir a primeira palavra em inglês. Como o token atual do decoder é o início da sequência, efetivamente o modelo está perguntando: Qual deveria ser a primeira palavra da tradução? A atenção cruzada permitirá que o decoder olhe para todos os vetores do encoder. Provavelmente, ele dará muita atenção ao vetor do encoder correspondente a “gato” (sujeito da frase) e talvez ao “telhado” se necessário, e decidirá que a primeira palavra em inglês deve ser “The” (uma vez que “O gato” vira “The cat”). Note que essa decisão ainda não é totalmente “verbalizada” aqui – é uma predisposição nos vetores.
- Decoder – Saída da Camada 1: Após a atenção cruzada e outra passagem por feed-forward dentro da camada 1 do decoder, o vetor resultante representa a melhor hipótese do modelo para o início da frase traduzida, incorporando tanto o que já havia no decoder (“[inicio]”) quanto a consulta ao encoder (frase original).
- Geração do Primeiro Token de Saída: O decoder agora passa esse vetor para a última etapa linear + softmax (uma camada final do modelo que mapeia vetores para probabilidades sobre o vocabulário de saída). Essa etapa produz uma distribuição de probabilidade para qual token em inglês deve ser o primeiro. Digamos que “The” tenha a maior probabilidade. Então o modelo escolhe “The” como o primeiro token de saída gerado.
- Feedback do Primeiro Token: O token “The” é então alimentado de volta no decoder (agora a sequência de saída parcial é “[inicio] The”). O processo itera: geramos um embedding para “The” com posição 2 (lembrando que posição 1 era “[inicio]”).
- Decoder – Camada 1 (2ª iteração, Atenção Mascarada): Agora com dois tokens no decoder (“[inicio]” e “The”), a atenção mascarada entra em ação de verdade. Ao calcular a atenção para a posição atual (que corresponde a “The”), o modelo mascara o token futuro (que ainda não existe) mas considera o token passado (“[inicio]”). Assim, “The” pode olhar para “[inicio]” se precisar, mas não há nada além dele. Essencialmente, aqui a atenção mascarada garante que “The” não veja nenhum token que venha depois dele na saída (o que está de acordo, pois não existe ainda).
- Decoder – Camada 1 (2ª iteração, Atenção Cruzada): Em seguida, com o vetor atualizado de “The” após atenção mascarada, o modelo faz atenção cruzada com os vetores do encoder novamente. Agora a pergunta interna é: Dado que já comecei a frase em inglês com “The”, qual é a próxima palavra? O modelo, via atenção cruzada, provavelmente olha para o vetor do encoder de “gato” e entende que precisa traduzir “gato”. A palavra em inglês para “gato” é “cat”. Ele também sabe que “The” foi emitido antes possivelmente porque “O” é artigo definido. Então é provável que o próximo token seja um substantivo correspondente a “gato”.
- Geração do Segundo Token: Após passar por todos os subcomponentes da camada (atenção mascarada, cruzada, feed-forward) e possivelmente outras camadas do decoder (camada 2, 3, … repetindo o processo para maior refinamento), o modelo produz a distribuição de probabilidade para o segundo token. “cat” aparece com alta probabilidade e é escolhido. Agora temos “[inicio] The cat” gerado.
- Iteração até Finalizar: O decoder continua esse ciclo token a token. Na terceira palavra, a sequência parcial “[inicio] The cat” estará presente, e a atenção mascarada garantirá que a terceira palavra atente a “The” e “cat” mas nada depois. A atenção cruzada usará o contexto do encoder – possivelmente agora vai focar nos vetores de “está no telhado” para descobrir que depois de “The cat”, a frase deve expressar que ele “está no telhado”. Provavelmente escolherá “is” como próxima palavra, depois “on”, depois “the”, depois “roof”, até que toda a frase “The cat is on the roof” esteja gerada. Por fim, o modelo gera um token de fim de sequência para indicar que a tradução terminou.
- Resultado: A frase de saída em inglês é montada juntando todos os tokens gerados: “The cat is on the roof.”, que corresponde à tradução esperada. 🎉
Nesse exemplo, observamos como cada componente do Transformer colabora: os embeddings e posições fornecem a base, o encoder constrói entendimento global da frase em português, e o decoder – usando atenção mascarada para seguir passo a passo – produz a frase em inglês consultando o que o encoder aprendeu. Em aplicações reais, tudo isso acontece através de operações matriciais e vetoriais de alta dimensão, mas conceitualmente o processo é esse.
Conclusão
Os Transformers redefiniram os limites do que é possível em inteligência artificial nos últimos anos. Graças à sua arquitetura baseada em atenção, eles conseguem capturar contexto de forma mais eficaz do que modelos anteriores e processar informações em paralelo, o que os torna escaláveis para volumes massivos de dadostoolify.aidolutech.com. Hoje, a arquitetura Transformer é o alicerce de praticamente todos os grandes modelos de linguagem, incluindo tradutores automáticos, assistentes virtuais e o próprio ChatGPT, demonstrando sua eficácia em gerar textos coerentes e contextualmente relevantesGoogle DriveGoogle Drive.
Além do PLN, os Transformers encontram-se no coração de sistemas de visão computacional (como modelos que descrevem imagens ou reconhecem objetos), de modelos de áudio (reconhecimento e síntese de voz) e até em avanços científicos, como previsão de estruturas de proteínas ou sequenciamento genéticoen.wikipedia.orgdolutech.com. Sua versatilidade vem justamente da forma genérica como tratam dados sequenciais e relacionamentos – basta ter “elementos que se relacionam”, seja em texto, imagem ou outro domínio, que a atenção do Transformer pode ser aplicada.
O futuro aponta para Transformers ainda maiores e mais especializados. Novas pesquisas exploram modelos multimodais, que combinam texto, imagem e áudio na mesma arquitetura, bem como melhorias na eficiência computacional, já que o custo de processamento dos Transformers cresce quadraticamente com o tamanho da sequência (o que motiva inovações como sparse attention, flash attention, etc.). Também vemos variações híbridas e ajustes finos que tornam esses modelos mais controláveis e melhores em seguir instruções humanas.
Em suma, compreender a arquitetura Transformer é fundamental para entender a atual revolução da IA. Ela nos mostrou que “atenção” é realmente tudo de que precisamos – ao permitir que modelos imitem a capacidade humana de focar nos detalhes certos, os Transformers abriram caminho para sistemas de IA mais inteligentes, flexíveis e eficientes. E com a contínua evolução dessa arquitetura, podemos esperar aplicações ainda mais impressionantes, desde assistentes pessoais cada vez mais inteligentes até avanços em áreas que ainda estamos começando a explorar. O Transformer se tornou, sem dúvida, uma pedra angular da IA moderna, e seu impacto continuará a se fazer sentir nas inovações dos anos que virão.
Autor: André Cardia
Referências Bibliográficas
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017).
Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
Disponível em: https://arxiv.org/abs/1706.03762 - Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020).
Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
Disponível em: https://arxiv.org/abs/2005.14165 - Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018).
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint.
Disponível em: https://arxiv.org/abs/1810.04805 - OpenAI. (2023).
GPT-4 Technical Report.
Disponível em: https://cdn.openai.com/papers/gpt-4.pdf - Alammar, J. (2018).
The Illustrated Transformer.
Disponível em: http://jalammar.github.io/illustrated-transformer/
